.png)
So sánh Bảng tính và Sơ sở dữ liệu: nên sử dụng định dạng bảng nào?
Hình dáng của một tập dữ liệu rất quan trọng đối với việc dữ liệu có thể được xử lý như thế nào bởi các phần mềm khác nhau. Hình dạng xác định cách dữ liệu được trình bày: theo chiều rộng như trong bảng tính hoặc dài như trong bảng cơ sở dữ liệu.
Mỗi loại hình dáng này đều có công dụng riêng, nhưng điều quan trọng là bạn phải hiểu sự khác biệt của chúng và biết khi nào nên sử dụng định dạng bảng ngang như một Bảng tính và dọc như một Cơ sở dữ liệu.

Bảng tính: rộng và có hai chiều
Bảng tính được trình bày theo hai chiều. Đó có lẽ là tính năng cơ bản nhất và quan trọng nhất của chúng. Chúng có ý nghĩa đối với chúng ta vì chúng ta có thể dễ dàng suy nghĩ và sắp xếp mọi thứ theo cách hợp lý.
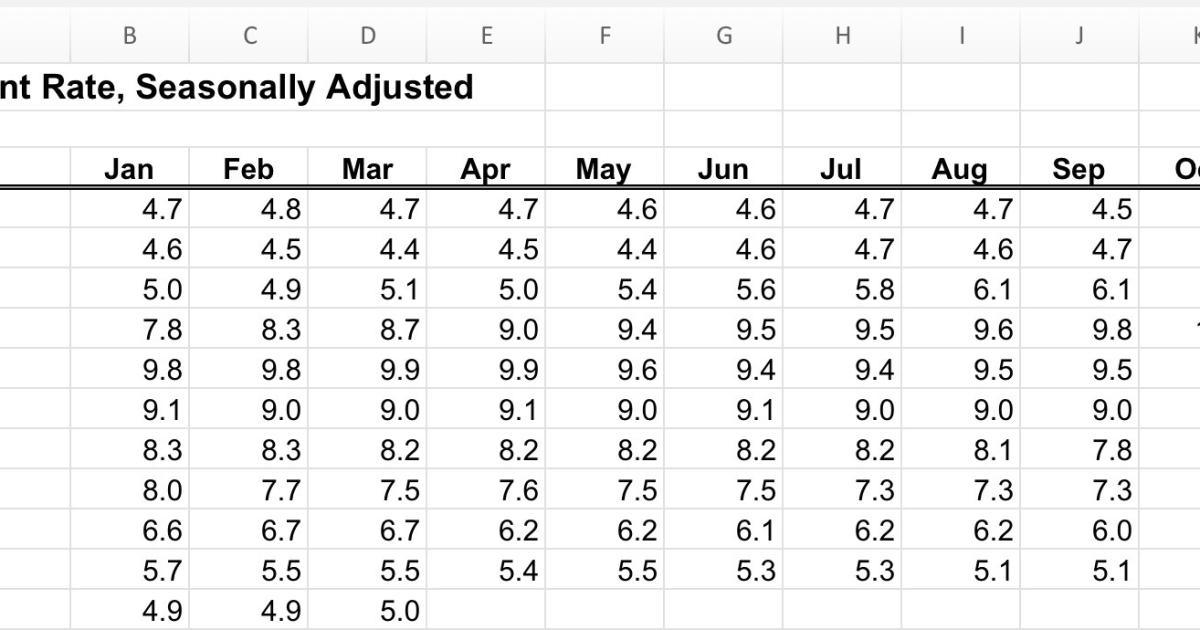
Bố cục lưới trong trường hợp này vô cùng hiệu quả vì bạn không phải lặp lại những gì đang được hiển thị. Trong ví dụ về dữ liệu thất nghiệp này, mỗi hàng là một năm và mỗi cột một tháng. Nếu bạn đang tìm kiếm, giả sử vào tháng 4 năm 2010, bạn biết phải tìm ở đâu. Và bạn có thể dễ dàng đọc thời gian của năm tiếp theo hoặc năm trước đó, tùy thuộc vào việc bạn đang muốn so sánh giữa các tháng hoặc năm qua năm.
Các phép tính cũng dễ thực hiện: tính tổng các hàng trên, tính tổng các cột xuống, lấy giá trị trung bình, tạo một cột mới với sự khác biệt của mỗi hàng so với giá trị trung bình tổng thể, …
Tất nhiên là có những hạn chế. Nếu bạn muốn chia nhỏ dữ liệu theo nhiều cách, bạn cần tạo nhiều bảng. Điều này cũng đúng khi thêm nhiều số hơn vào mỗi ô. Bạn có thể muốn so sánh tỷ lệ thất nghiệp với lực lượng lao động hoặc trình độ học vấn, nhưng chúng ở các bảng khác nhau, khiến cho việc so sánh trở nên phức tạp.
Đối với các công cụ phân tích dữ liệu, bảng tính cũng đặt ra thách thức là định dạng của chúng có thể rất khác nhau và thường không nhất quán . Một vấn đề khác nữa là thường có nhiều thứ xung quanh dữ liệu thực tế, để giải thích mọi thứ, khiến một chương trình khó có thể nhận ra dữ liệu thực tế là gì.
Bên cạnh đó các tiêu đề cột không cho bạn biết ý nghĩa của chúng. Trong ví dụ trên, Năm có nghĩa là mỗi số trong cột đó là một năm. Nhưng tháng 1 , tháng 2 , ... thì không, chúng thực sự là một phần của ngày tháng và do đó, cũng là một phần của dữ liệu. Làm thế nào để một chương trình có thể nhận ra và phân biệt chúng?
Mọi người có thể dễ dàng hiểu các quy ước trong một bảng tính, ví dụ như các cột trong bảng bên dưới này giống như trong bảng ở trên, nhãn duy nhất đó áp dụng cho tất cả các hàng,... nhưng máy tính thì không thể tìm ra.
Cơ sở dữ liệu: Dài và hẹp
Đối lập với bảng tính là bảng cơ sở dữ liệu. Thay vì sắp xếp dữ liệu theo hai chiều, cơ sở dữ liệu là một danh sách dài. Nó có các cột, nhưng không nhiều lắm, trong một bảng cơ sở dữ liệu.
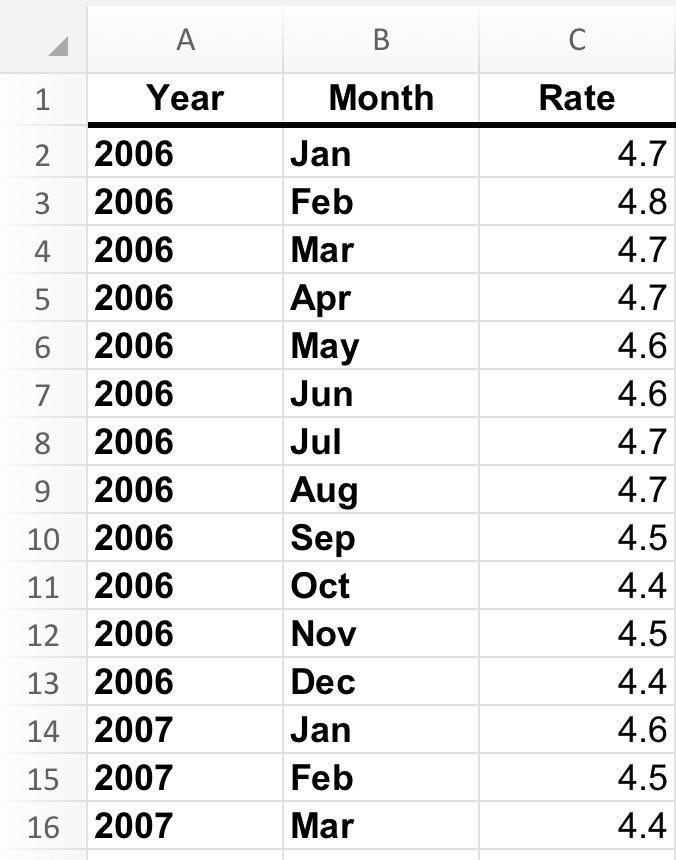
Thay vào đó, mỗi cột có một vai trò. Trong ví dụ về tỷ lệ thất nghiệp của chúng ta ở trên, có một cột cho năm, một cho tháng và sau đó là cột cuối cùng cho giá trị thực tế. Đây không phải là một định dạng dễ hiểu cho con người, nhưng máy móc lại thích nó.
Định dạng này gây ra sự lặp lại. Hàng đầu tiên đại diện cho tháng 1 năm 2006, vì vậy nó phải chứa năm 2006 và sau đó là tháng 1. Mục tiếp theo, tháng 2 năm 2006, phải lặp lại năm. Và một năm sau, tháng đó lại lặp lại. Có vẻ như cần rất nhiều nỗ lực để biểu diễn dữ liệu theo cách này, nhưng theo cách này, tất cả đều được chỉ định. Và hầu hết các cơ sở dữ liệu ngày nay có thể nén loại dữ liệu lặp đi lặp lại này nên trên thực tế, bảng cơ sở dữ liệu như trên chiếm rất ít dung lượng.
Cấu trúc đồng nhất của định dạng này giúp bạn dễ dàng thực hiện tất cả các loại hoạt động, như lọc ra các giá trị nhất định, tính toán sự khác biệt, giá trị trung bình,... và tất cả những thứ khác mà cơ sở dữ liệu mang lại hiệu quả.
Định dạng này cũng linh hoạt hơn nhiều khi có thêm nhiều cách chia nhỏ dữ liệu hoặc thêm nhiều phép đo hơn. Bạn có muốn tính tỷ lệ thất nghiệp cho mỗi khu vực không? Trong mô hình bảng tính, bạn phải tạo nhiều bảng, một bảng cho mỗi trạng thái. Hoặc bạn có thể lập các bảng lớn hơn cho từng khu vực theo tháng và các bảng khác nhau cho mỗi năm. Điều này có vẻ kỳ quặc, nhưng các bảng đó sẽ cho phép so sánh giữa các tiểu bang qua mỗi năm.
Ở định dạng dài và hẹp này, bạn chỉ cần thêm một cột trạng thái và máy tính sẽ lo điều còn lại. Vẽ biểu đồ với một đường mỗi trạng thái theo thời gian? Tính toán sự thay đổi qua từng năm cho từng loại?…
Các cột chia nhỏ dữ liệu như vậy được gọi là dimension. Các bảng cơ sở dữ liệu thường chứa hàng tá dimension như thế. Các số được liên kết với mỗi tổ hợp giá trị dimension được gọi là metric. Và những metric cũng dễ thêm vào. Muốn lực lượng lao động ngoài tỷ lệ thất nghiệp? Chỉ cần thêm một cột. Tương tự như vậy đối với dân số, chi phí sinh hoạt, …
Việc có tất cả dữ liệu đó ở cùng một nơi sẽ tạo ra nhiều so sánh, tùy thuộc vào người đặt câu hỏi và không cần phải chuẩn bị trước như các bảng tính. Đó là lý do tại sao dữ liệu kiểu database dài và hẹp như thế này thân thiện với máy móc hơn là con người: máy móc có thể biến dữ liệu thân thiện với máy móc thành tất cả các loại định dạng mà con người có thể đọc được, nhưng ngược lại thì khó và dễ xảy ra lỗi hơn nhiều.
Biến Bảng tính thành Cơ sở dữ liệu và ngược lại: (Un-)Pivot
Hai hình dạng này trông khác nhau và chúng hữu ích trong các bối cảnh khác nhau. Nhưng chúng đại diện cho cùng một dữ liệu. Bạn có thể chuyển bảng tính thành cơ sở dữ liệu và người lại. Thao tác này có dễ dàng hay không phụ thuộc vào các công cụ có sẵn và một số chi tiết cụ thể bên trong dữ liệu.
Thuật ngữ để chuyển định dạng cơ sở dữ liệu dài hạn thành định dạng bảng tính rộng thường là xoay dữ liệu - pivot. Thao tác này khá dễ dàng vì máy biết tìm dữ liệu ở đâu và chỉ cần cho biết dimension nào sẽ sử dụng để tạo cột và bao gồm các số liệu nào.
Thao tác khác, thao tác unpivot, thường khó hơn nhiều và dễ xảy ra lỗi. Khi dữ liệu đã ở định dạng bảng thích hợp (với tất cả những thứ xung quanh dữ liệu thuần túy đã bị xóa), nó vẫn hoạt động tốt.
Không có định dạng bảng nào là tốt nhất
Cả hai hình dạng dữ liệu này đều không đúng hay sai. Mỗi loại định dạng đều hoạt động tốt cho các mục đích sử dụng tương ứng. Điều khó khăn nhất ở đây là bạn phải xác định định dạng bảng phù hợp nhất cho mục đích sử dụng của mình.
Về cơ bản hơn, điều quan trọng là phải biết rằng những khác biệt về hình dạng dữ liệu này có tồn tại. Đó là bước đầu tiên trong việc cố gắng tìm ra lý do tại sao một tập dữ liệu cụ thể lại rất khó làm việc với công cụ bạn chọn. Bạn sẽ không hài lòng lắm với một tập dữ liệu rộng trong Table hay Google data studio, nhưng cũng sẽ không thấy hài lòng với một tập dữ liệu dài và hẹp trong Excel.
Hy vọng, với bài viết này, bạn đã chọn được định dạng bảng phù hợp cho tập dữ liệu của mình. Bên cạnh đó, để không bỏ lỡ những mẹo và thủ thuật tin học văn phòng hữu ích khác, hãy theo dõi Gitiho ngay hôm nay.
Khóa học phù hợp với bất kỳ ai đang muốn tìm hiểu lại Excel từ con số 0. Giáo án được Gitiho cùng giảng viên thiết kế phù hợp với công việc thực tế tại doanh nghiệp, bài tập thực hành xuyên suốt khóa kèm đáp án và hướng dẫn giải chi tiết. Tham khảo ngay bên dưới!

Bài viết liên quan
Giấy chứng nhận Đăng ký doanh nghiệp số: 0109077145, cấp bởi Sở kế hoạch và đầu tư TP. Hà Nội
Giấy phép mạng xã hội số: 588, cấp bởi Bộ thông tin và truyền thông